회사 세미나를 위해 논문을 읽어보자!
이 논문은 요즘 핫한 speculative decoding을 처음 소개한 논문이라 선택했다.
퀄컴에서도 이 기술을 채택한다는 소문이 있는데, 더더욱 잘 알아둬야 할 것 같다.
DNN model의 inference 속도를 높이기 위한 다양한 접근법이 있었는데, 대표적인 예시로는 adaptive computation이 있다. Adaptive computation은 input의 complexity라던가 여러 가지 조건에 따라 자원 분배를 줄여 inference를 가속한다. 한창 대학원 다닐 때 유행했던 Early Exit이 대표적인 Adaptive Computation인데, model의 곳곳에 exit point를 만들어서 confidence가 충분히 높아지면 이후의 layer를 거르고 바로 exit point로 탈출해서 결과를 낸다. 이러한 adaptive computation은 매우 효과적이었지만, 아래와 같은 치명적인 문제가 있었다.
- model architecture를 변경해야 한다
- training-procedure를 변경하고 re-training을 해야한다
- 변형하기 전과 output이 미묘하게 달라진다
본 논문에서 제안하는 speculative decoding은speculative execution(1985)에서 아이디어를 얻었다.
speculative execution이란 어떤 작업이, 그 작업이 진짜로 필요한지 검증하는 작업과 동시에 이루어지는 것을 의미한다. 대표적인 speculative execution이 바로 익히 알려진 branch prediction이다.
본 논문에서는 decoding의 bottleneck이 computation이 아닌 memory bandwidth와 commucation에 있음을 착안해서, 한 번에 여러 개의 토큰을 speculative하게 연산하고 이들을 한번에 검증하는 새로운 decoding 방식을 제안한다.
key ideas는 다음과 같다.
- Speculative sampling: speculative task의 적중률 최대화 및 원본 model과 완전히 동일한 결과 보장
- Speculative decoding: target model보다 빠른 approximation model을 통한 빠른 decoding
Speculative Decoding

기존의 decoding 방식은 다음 토큰을 생성하기 위해 직전까지의 토큰들을 필요로 하기 때문에 무조건 sequential하게 토큰을 생성한다.

- Target model(Mp): 가속할 원본 model.
- Approximation Model(Mq): Mp와 같은 작업을 수행하지만 더 작고 효율적인 model.
이 두 모델을 사용해서 decoding하는 순서는 다음과 같다.
- Mq를 통해 γ 개의 토큰을 생성. 원본 모델처럼 sequential하게 생성하지만 model이 작아서 훨씬 빠름
- Mp는 Mq가 생성한 모든 토큰을 한 번에 parallel하게 평가하고 확률 분포를 생성
- Mq가 생성한 토큰 중 거절당한 것이 있을 경우 해당 토큰을 수정하고 이후의 토큰을 전부 폐기, 이후 1번으로 돌아가 새로운 토큰을 생성
위 그림에서도 'ate'는 통과했지만 'the'는 reject당해서 'my'로 수정되고, 'the'를 input으로 하여 생성된 'dog'는 그대로 폐기되는 것을 확인할 수 있다.
이 방식을 통해 한 번의 parallel excution(생성 + 검증)으로 최소 한 개의 토큰을 생성할 수 있고, 첫 토큰이 전부 reject당한 최악의 경우에도 기존의 sequential한 실행과 동일한 반복 횟수를 가진다.
또한 reject되지 않은 토큰이 있을 경우 같은 iteration으로 기존 model보다 더 많은 토큰을 생성할 수 있다.

이를 타임라인으로 보면 위와 같은 형태가 된다.
파란색의 Mq decoding이 끼면서 iteration 한 번은 약간 길어졌지만, Mq의 토큰당 decoding 시간은 Mp의 5% 미만이기 때문에 토큰을 몇 개 생성한다고 해도 iteration이 과하게 두툼해지진 않는다.
하지만 토큰이 iteration당 두 개 정도만 생성되어주어도 실행 시간은 거의 절반 가까이로 줄어든다.
Speculative Sampling
- p(x): Mp가 생성한 distribution
- q(x): Mq가 생성한 distribution
q(x) ≤ p(x)인 경우에는 해당 sample을 수용
q(x) > p(x)인 경우 1−p(x)/q(x)의 확률로 해당 sample을 거절하고 수정된 p'(x)로부터 새로운 sample x를 얻는다.
Analysis
Token Generation

E(β): Mq가 Mp를 얼마나 잘 모방하는지 나타내는 지표. 1에서 Mq와 Mp의 결과값의 차이를 뺀 것
α: E(β)의 기댓값
토큰 생성 수: 1 − α ^ (γ + 1) / (1 − α)
간단히 설명하면 α는 Mq에서 생성한 토큰을 Mp가 검증했을 때 통과될 확률이다.
γ는 아까 언급한 것과 마찬가지로, Mq가 한 번에 생성한 후 Mp에게 넘기는 토큰의 개수이다.
α와 γ가 커질수록 iteration 한 번에 생성되어 수용되는 토큰 개수의 기댓값이 늘어난다.
Walltime Improvement & Choosing γ
토큰을 1 − α ^ (γ + 1) / (1 − α)개 더 생성한다는 건, 반대로 같은 결과물을 내기 위해 1 − α ^ (γ + 1) / (1 − α)번의 iteration을 덜 돈다는 뜻이다.
Walltime Improvement 계산에 있어서 Compute power는 무한하다고 가정한다.
c: cost efficient. Mq single run과 Mp single run의 시간 비율. 모델에 따라 고정된 α와 달리 HW/SW configuration에 따라 변화하며 일반적으로 < 0.05
생성되는 토큰 개수에 c값을 적용해서 계산한 Walltime Improvement 공식은 다음과 같다.

공식에 따르면 α > c일때 Walltime improvement가 발생하는데, c는 0.05 미만의 작은 값이므로 이 조건은 쉽게 충족된다.
α와 c는 각각 Mq와 configuration에 따라 불변하는 값이므로 이 값을 최대화하기 위해서 γ값의 조정이 필요하다.
α > c 조건만 만족하면 무조건 walltime improvement가 발생한다는 사실은 이후 재미있는 아이디어로 이어진다.
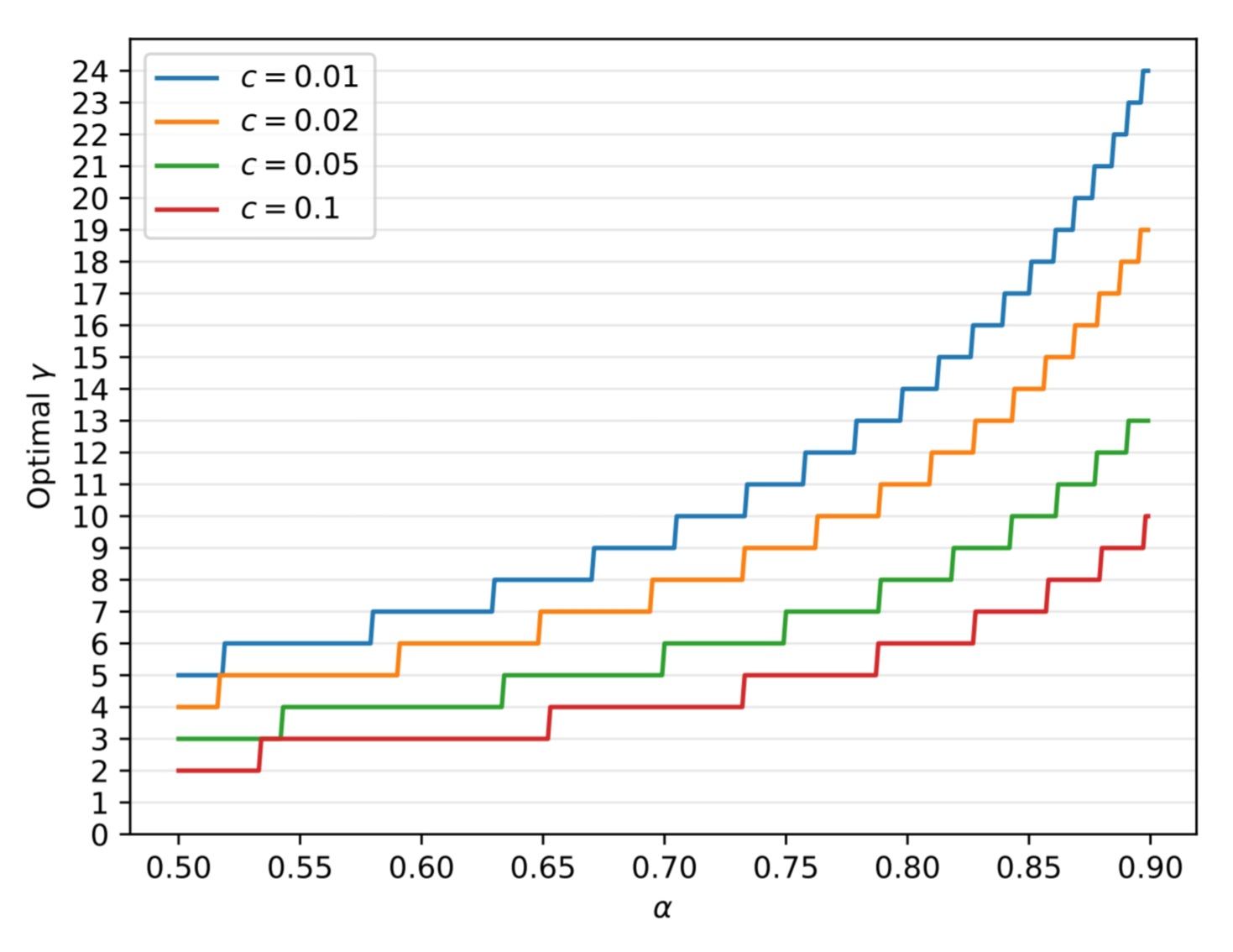
이상적인 γ값은 α값에 따라 위 그래프와 같이 분포한다.
Approximation Models
본 논문에서 사용한 Approximation Model들은 다음과 같다.
- 공개된 작은 Transformer 모델: 가장 정석적이다. Mq가 Mp의 1% 미만의 사이즈일 때 α와 c의 비율이 가장 우수했다.
- negligible-cost-model: c~0으로 수렴한다. computation cost가 매우 작아서 γ를 극대화할 수 있고, γ를 극대화하면 walltime improvement가 1 / (1 - α)가 되므로 α가 non-zero기만 하면 walltime improvement를 얻을 수 있다.
- non-autoregressive model
- 무작위의 token을 생성하는 approximation model: negligible-cost-model과 유사하지만 정확도가 매우 떨어진다. 대신 그 어떤 Mp에 대해서도 약간의 walltime improvement를 얻을 수 있다.
Experiments


'코딩' 카테고리의 다른 글
| 라떼판다 알파 개봉기 (0) | 2023.11.23 |
|---|